TensorFlow常用模块¶
前置知识
Python的序列化模块Pickle (非必须)
Python的特殊函数参数**kwargs (非必须)
tf.train.Checkpoint :变量的保存与恢复¶
警告
Checkpoint只保存模型的参数,不保存模型的计算过程,因此一般用于在具有模型源代码的时候恢复之前训练好的模型参数。如果需要导出模型(无需源代码也能运行模型),请参考 “部署”章节中的SavedModel 。
很多时候,我们希望在模型训练完成后能将训练好的参数(变量)保存起来。在需要使用模型的其他地方载入模型和参数,就能直接得到训练好的模型。可能你第一个想到的是用Python的序列化模块 pickle 存储 model.variables。但不幸的是,TensorFlow的变量类型 ResourceVariable 并不能被序列化。
好在TensorFlow提供了 tf.train.Checkpoint 这一强大的变量保存与恢复类,可以使用其 save() 和 restore() 方法将TensorFlow中所有包含Checkpointable State的对象进行保存和恢复。具体而言,tf.keras.optimizer 、 tf.Variable 、 tf.keras.Layer 或者 tf.keras.Model 实例都可以被保存。其使用方法非常简单,我们首先声明一个Checkpoint:
checkpoint = tf.train.Checkpoint(model=model)
这里 tf.train.Checkpoint() 接受的初始化参数比较特殊,是一个 **kwargs 。具体而言,是一系列的键值对,键名可以随意取,值为需要保存的对象。例如,如果我们希望保存一个继承 tf.keras.Model 的模型实例 model 和一个继承 tf.train.Optimizer 的优化器 optimizer ,我们可以这样写:
checkpoint = tf.train.Checkpoint(myAwesomeModel=model, myAwesomeOptimizer=optimizer)
这里 myAwesomeModel 是我们为待保存的模型 model 所取的任意键名。注意,在恢复变量的时候,我们还将使用这一键名。
接下来,当模型训练完成需要保存的时候,使用:
checkpoint.save(save_path_with_prefix)
就可以。 save_path_with_prefix 是保存文件的目录+前缀。
注解
例如,在源代码目录建立一个名为save的文件夹并调用一次 checkpoint.save('./save/model.ckpt') ,我们就可以在可以在save目录下发现名为 checkpoint 、 model.ckpt-1.index 、 model.ckpt-1.data-00000-of-00001 的三个文件,这些文件就记录了变量信息。checkpoint.save() 方法可以运行多次,每运行一次都会得到一个.index文件和.data文件,序号依次累加。
当在其他地方需要为模型重新载入之前保存的参数时,需要再次实例化一个checkpoint,同时保持键名的一致。再调用checkpoint的restore方法。就像下面这样:
model_to_be_restored = MyModel() # 待恢复参数的同一模型
checkpoint = tf.train.Checkpoint(myAwesomeModel=model_to_be_restored) # 键名保持为“myAwesomeModel”
checkpoint.restore(save_path_with_prefix_and_index)
即可恢复模型变量。 save_path_with_prefix_and_index 是之前保存的文件的目录+前缀+编号。例如,调用 checkpoint.restore('./save/model.ckpt-1') 就可以载入前缀为 model.ckpt ,序号为1的文件来恢复模型。
当保存了多个文件时,我们往往想载入最近的一个。可以使用 tf.train.latest_checkpoint(save_path) 这个辅助函数返回目录下最近一次checkpoint的文件名。例如如果save目录下有 model.ckpt-1.index 到 model.ckpt-10.index 的10个保存文件, tf.train.latest_checkpoint('./save') 即返回 ./save/model.ckpt-10 。
总体而言,恢复与保存变量的典型代码框架如下:
# train.py 模型训练阶段
model = MyModel()
# 实例化Checkpoint,指定保存对象为model(如果需要保存Optimizer的参数也可加入)
checkpoint = tf.train.Checkpoint(myModel=model)
# ...(模型训练代码)
# 模型训练完毕后将参数保存到文件(也可以在模型训练过程中每隔一段时间就保存一次)
checkpoint.save('./save/model.ckpt')
# test.py 模型使用阶段
model = MyModel()
checkpoint = tf.train.Checkpoint(myModel=model) # 实例化Checkpoint,指定恢复对象为model
checkpoint.restore(tf.train.latest_checkpoint('./save')) # 从文件恢复模型参数
# 模型使用代码
注解
tf.train.Checkpoint 与以前版本常用的 tf.train.Saver 相比,强大之处在于其支持在即时执行模式下“延迟”恢复变量。具体而言,当调用了 checkpoint.restore() ,但模型中的变量还没有被建立的时候,Checkpoint可以等到变量被建立的时候再进行数值的恢复。即时执行模式下,模型中各个层的初始化和变量的建立是在模型第一次被调用的时候才进行的(好处在于可以根据输入的张量形状而自动确定变量形状,无需手动指定)。这意味着当模型刚刚被实例化的时候,其实里面还一个变量都没有,这时候使用以往的方式去恢复变量数值是一定会报错的。比如,你可以试试在train.py调用 tf.keras.Model 的 save_weight() 方法保存model的参数,并在test.py中实例化model后立即调用 load_weight() 方法,就会出错,只有当调用了一遍model之后再运行 load_weight() 方法才能得到正确的结果。可见, tf.train.Checkpoint 在这种情况下可以给我们带来相当大的便利。另外, tf.train.Checkpoint 同时也支持图执行模式。
最后提供一个实例,以前章的 多层感知机模型 为例展示模型变量的保存和载入:
import tensorflow as tf
import numpy as np
import argparse
from zh.model.mnist.mlp import MLP
from zh.model.utils import MNISTLoader
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('--mode', default='train', help='train or test')
parser.add_argument('--num_epochs', default=1)
parser.add_argument('--batch_size', default=50)
parser.add_argument('--learning_rate', default=0.001)
args = parser.parse_args()
data_loader = MNISTLoader()
def train():
model = MLP()
optimizer = tf.keras.optimizers.Adam(learning_rate=args.learning_rate)
num_batches = int(data_loader.num_train_data // args.batch_size * args.num_epochs)
checkpoint = tf.train.Checkpoint(myAwesomeModel=model) # 实例化Checkpoint,设置保存对象为model
for batch_index in range(1, num_batches+1):
X, y = data_loader.get_batch(args.batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
if batch_index % 100 == 0: # 每隔100个Batch保存一次
path = checkpoint.save('./save/model.ckpt') # 保存模型参数到文件
print("model saved to %s" % path)
def test():
model_to_be_restored = MLP()
# 实例化Checkpoint,设置恢复对象为新建立的模型model_to_be_restored
checkpoint = tf.train.Checkpoint(myAwesomeModel=model_to_be_restored)
checkpoint.restore(tf.train.latest_checkpoint('./save')) # 从文件恢复模型参数
y_pred = np.argmax(model_to_be_restored.predict(data_loader.test_data), axis=-1)
print("test accuracy: %f" % (sum(y_pred == data_loader.test_label) / data_loader.num_test_data))
if __name__ == '__main__':
if args.mode == 'train':
train()
if args.mode == 'test':
test()
在代码目录下建立save文件夹并运行代码进行训练后,save文件夹内将会存放每隔100个batch保存一次的模型变量数据。在命令行参数中加入 --mode=test 并再次运行代码,将直接使用最后一次保存的变量值恢复模型并在测试集上测试模型性能,可以直接获得95%左右的准确率。
使用 tf.train.CheckpointManager 删除旧的Checkpoint以及自定义文件编号
在模型的训练过程中,我们往往每隔一定步数保存一个Checkpoint并进行编号。不过很多时候我们会有这样的需求:
在长时间的训练后,程序会保存大量的Checkpoint,但我们只想保留最后的几个Checkpoint;
Checkpoint默认从1开始编号,每次累加1,但我们可能希望使用别的编号方式(例如使用当前Batch的编号作为文件编号)。
这时,我们可以使用TensorFlow的 tf.train.CheckpointManager 来实现以上需求。具体而言,在定义Checkpoint后接着定义一个CheckpointManager:
checkpoint = tf.train.Checkpoint(model=model)
manager = tf.train.CheckpointManager(checkpoint, directory='./save', checkpoint_name='model.ckpt', max_to_keep=k)
此处, directory 参数为文件保存的路径, checkpoint_name 为文件名前缀(不提供则默认为 ckpt ), max_to_keep 为保留的Checkpoint数目。
在需要保存模型的时候,我们直接使用 manager.save() 即可。如果我们希望自行指定保存的Checkpoint的编号,则可以在保存时加入 checkpoint_number 参数。例如 manager.save(checkpoint_number=100) 。
以下提供一个实例,展示使用CheckpointManager限制仅保留最后三个Checkpoint文件,并使用batch的编号作为Checkpoint的文件编号。
import tensorflow as tf
import numpy as np
import argparse
from zh.model.mnist.mlp import MLP
from zh.model.utils import MNISTLoader
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('--mode', default='train', help='train or test')
parser.add_argument('--num_epochs', default=1)
parser.add_argument('--batch_size', default=50)
parser.add_argument('--learning_rate', default=0.001)
args = parser.parse_args()
data_loader = MNISTLoader()
def train():
model = MLP()
optimizer = tf.keras.optimizers.Adam(learning_rate=args.learning_rate)
num_batches = int(data_loader.num_train_data // args.batch_size * args.num_epochs)
checkpoint = tf.train.Checkpoint(myAwesomeModel=model)
# 使用tf.train.CheckpointManager管理Checkpoint
manager = tf.train.CheckpointManager(checkpoint, directory='./save', max_to_keep=3)
for batch_index in range(1, num_batches):
X, y = data_loader.get_batch(args.batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
if batch_index % 100 == 0:
# 使用CheckpointManager保存模型参数到文件并自定义编号
path = manager.save(checkpoint_number=batch_index)
print("model saved to %s" % path)
def test():
model_to_be_restored = MLP()
checkpoint = tf.train.Checkpoint(myAwesomeModel=model_to_be_restored)
checkpoint.restore(tf.train.latest_checkpoint('./save'))
y_pred = np.argmax(model_to_be_restored.predict(data_loader.test_data), axis=-1)
print("test accuracy: %f" % (sum(y_pred == data_loader.test_label) / data_loader.num_test_data))
if __name__ == '__main__':
if args.mode == 'train':
train()
if args.mode == 'test':
test()
TensorBoard:训练过程可视化¶
有时,你希望查看模型训练过程中各个参数的变化情况(例如损失函数loss的值)。虽然可以通过命令行输出来查看,但有时显得不够直观。而TensorBoard就是一个能够帮助我们将训练过程可视化的工具。
实时查看参数变化情况¶
首先在代码目录下建立一个文件夹(如 ./tensorboard )存放TensorBoard的记录文件,并在代码中实例化一个记录器:
summary_writer = tf.summary.create_file_writer('./tensorboard') # 参数为记录文件所保存的目录
接下来,当需要记录训练过程中的参数时,通过with语句指定希望使用的记录器,并对需要记录的参数(一般是scalar)运行 tf.summary.scalar(name, tensor, step=batch_index) ,即可将训练过程中参数在step时候的值记录下来。这里的step参数可根据自己的需要自行制定,一般可设置为当前训练过程中的batch序号。整体框架如下:
summary_writer = tf.summary.create_file_writer('./tensorboard')
# 开始模型训练
for batch_index in range(num_batches):
# ...(训练代码,当前batch的损失值放入变量loss中)
with summary_writer.as_default(): # 希望使用的记录器
tf.summary.scalar("loss", loss, step=batch_index)
tf.summary.scalar("MyScalar", my_scalar, step=batch_index) # 还可以添加其他自定义的变量
每运行一次 tf.summary.scalar() ,记录器就会向记录文件中写入一条记录。除了最简单的标量(scalar)以外,TensorBoard还可以对其他类型的数据(如图像,音频等)进行可视化,详见 TensorBoard文档 。
当我们要对训练过程可视化时,在代码目录打开终端(如需要的话进入TensorFlow的conda环境),运行:
tensorboard --logdir=./tensorboard
然后使用浏览器访问命令行程序所输出的网址(一般是http://name-of-your-computer:6006),即可访问TensorBoard的可视界面,如下图所示:
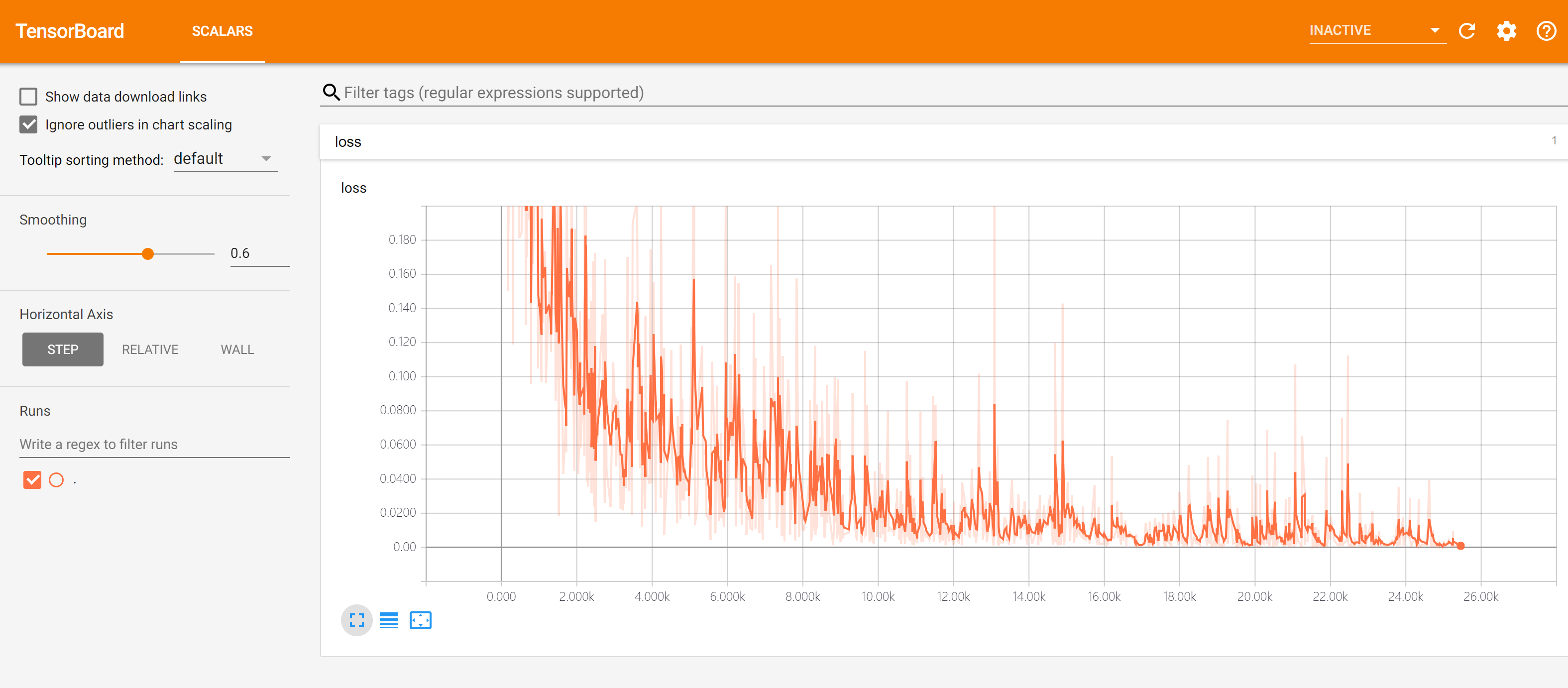
默认情况下,TensorBoard每30秒更新一次数据。不过也可以点击右上角的刷新按钮手动刷新。
TensorBoard的使用有以下注意事项:
如果需要重新训练,需要删除掉记录文件夹内的信息并重启TensorBoard(或者建立一个新的记录文件夹并开启TensorBoard,
--logdir参数设置为新建立的文件夹);记录文件夹目录保持全英文。
查看Graph和Profile信息¶
除此以外,我们可以在训练时使用 tf.summary.trace_on 开启Trace,此时TensorFlow会将训练时的大量信息(如计算图的结构,每个操作所耗费的时间等)记录下来。在训练完成后,使用 tf.summary.trace_export 将记录结果输出到文件。
tf.summary.trace_on(graph=True, profiler=True) # 开启Trace,可以记录图结构和profile信息
# 进行训练
with summary_writer.as_default():
tf.summary.trace_export(name="model_trace", step=0, profiler_outdir=log_dir) # 保存Trace信息到文件
之后,我们就可以在TensorBoard中选择“Profile”,以时间轴的方式查看各操作的耗时情况。如果使用了 tf.function 建立了计算图,也可以点击“Graphs”查看图结构。
提示
在 TensorFlow 2.3 及后续版本中,需要使用:
pip install -U tensorboard-plugin-profile
安装独立的 TensorBoard Profile 插件以使用 Profile 功能。
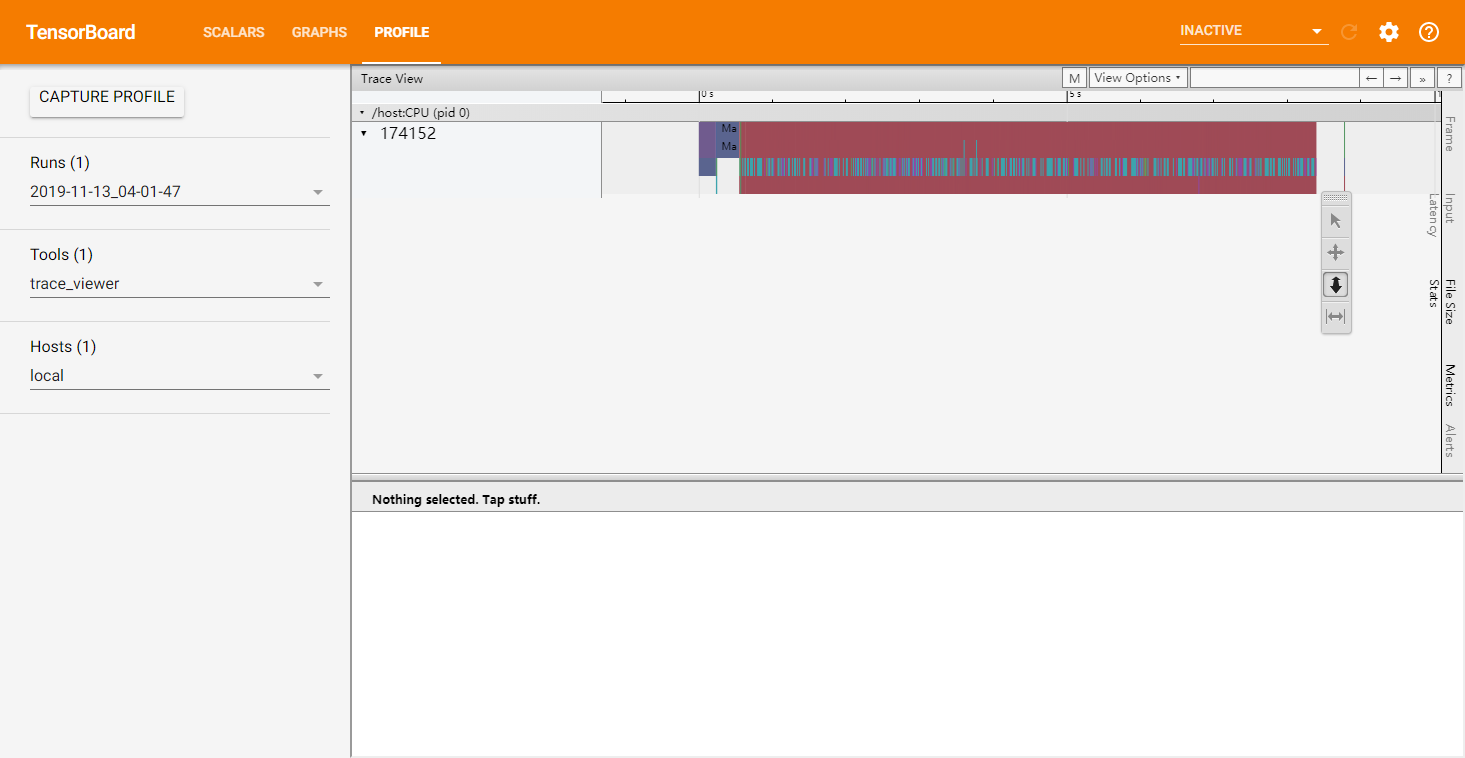
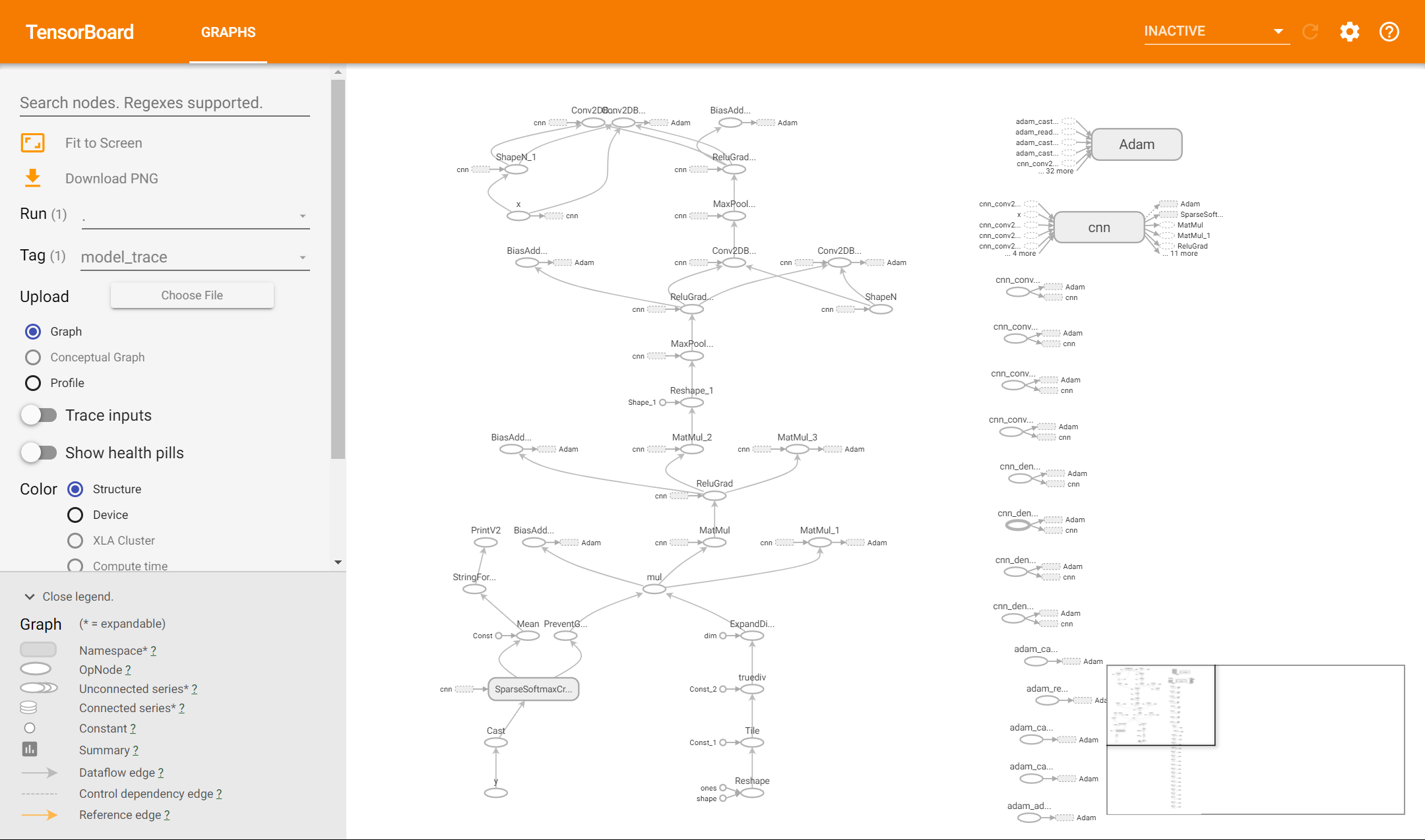
实例:查看多层感知机模型的训练情况¶
最后提供一个实例,以前章的 多层感知机模型 为例展示TensorBoard的使用:
import tensorflow as tf
from zh.model.mnist.mlp import MLP
from zh.model.utils import MNISTLoader
num_batches = 1000
batch_size = 50
learning_rate = 0.001
log_dir = 'tensorboard'
model = MLP()
data_loader = MNISTLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
summary_writer = tf.summary.create_file_writer(log_dir) # 实例化记录器
tf.summary.trace_on(profiler=True) # 开启Trace(可选)
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
with summary_writer.as_default(): # 指定记录器
tf.summary.scalar("loss", loss, step=batch_index) # 将当前损失函数的值写入记录器
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
with summary_writer.as_default():
tf.summary.trace_export(name="model_trace", step=0, profiler_outdir=log_dir) # 保存Trace信息到文件(可选)
tf.data :数据集的构建与预处理¶
很多时候,我们希望使用自己的数据集来训练模型。然而,面对一堆格式不一的原始数据文件,将其预处理并读入程序的过程往往十分繁琐,甚至比模型的设计还要耗费精力。比如,为了读入一批图像文件,我们可能需要纠结于python的各种图像处理包(比如 pillow ),自己设计Batch的生成方式,最后还可能在运行的效率上不尽如人意。为此,TensorFlow提供了 tf.data 这一模块,包括了一套灵活的数据集构建API,能够帮助我们快速、高效地构建数据输入的流水线,尤其适用于数据量巨大的场景。
数据集对象的建立¶
tf.data 的核心是 tf.data.Dataset 类,提供了对数据集的高层封装。tf.data.Dataset 由一系列的可迭代访问的元素(element)组成,每个元素包含一个或多个张量。比如说,对于一个由图像组成的数据集,每个元素可以是一个形状为 长×宽×通道数 的图片张量,也可以是由图片张量和图片标签张量组成的元组(Tuple)。
最基础的建立 tf.data.Dataset 的方法是使用 tf.data.Dataset.from_tensor_slices() ,适用于数据量较小(能够整个装进内存)的情况。具体而言,如果我们的数据集中的所有元素通过张量的第0维,拼接成一个大的张量(例如,前节的MNIST数据集的训练集即为一个 [60000, 28, 28, 1] 的张量,表示了60000张28*28的单通道灰度图像),那么我们提供一个这样的张量或者第0维大小相同的多个张量作为输入,即可按张量的第0维展开来构建数据集,数据集的元素数量为张量第 0 维的大小。具体示例如下:
import tensorflow as tf
import numpy as np
X = tf.constant([2013, 2014, 2015, 2016, 2017])
Y = tf.constant([12000, 14000, 15000, 16500, 17500])
# 也可以使用NumPy数组,效果相同
# X = np.array([2013, 2014, 2015, 2016, 2017])
# Y = np.array([12000, 14000, 15000, 16500, 17500])
dataset = tf.data.Dataset.from_tensor_slices((X, Y))
for x, y in dataset:
print(x.numpy(), y.numpy())
输出:
2013 12000
2014 14000
2015 15000
2016 16500
2017 17500
警告
当提供多个张量作为输入时,张量的第0维大小必须相同,且必须将多个张量作为元组(Tuple,即使用Python中的小括号)拼接并作为输入。
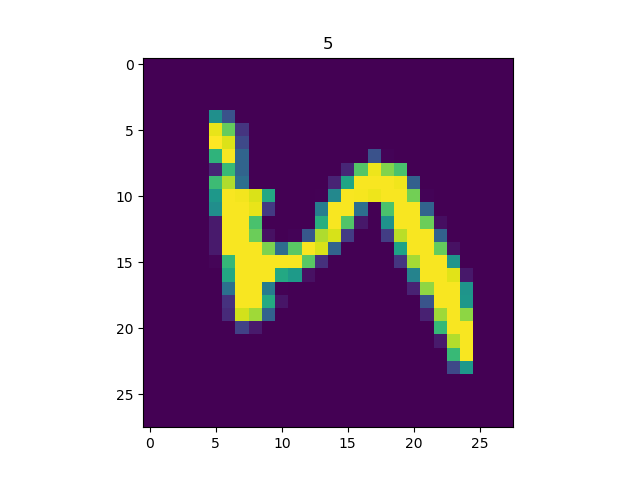
类似地,我们可以载入前章的MNIST数据集:
import matplotlib.pyplot as plt
(train_data, train_label), (_, _) = tf.keras.datasets.mnist.load_data()
train_data = np.expand_dims(train_data.astype(np.float32) / 255.0, axis=-1) # [60000, 28, 28, 1]
mnist_dataset = tf.data.Dataset.from_tensor_slices((train_data, train_label))
for image, label in mnist_dataset:
plt.title(label.numpy())
plt.imshow(image.numpy()[:, :, 0])
plt.show()
输出
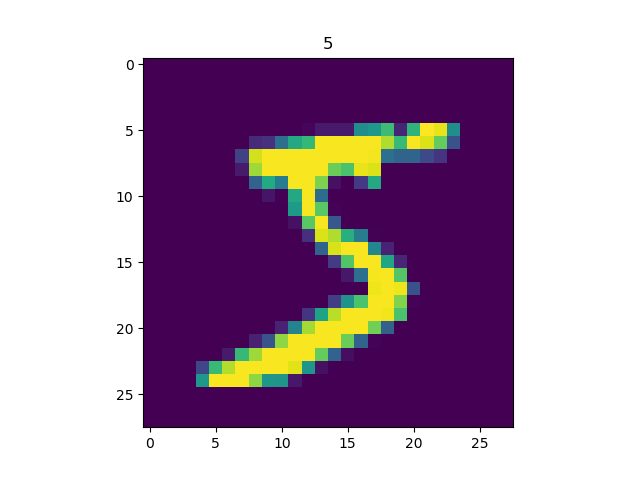
提示
TensorFlow Datasets提供了一个基于 tf.data.Datasets 的开箱即用的数据集集合,相关内容可参考 TensorFlow Datasets 。例如,使用以下语句:
import tensorflow_datasets as tfds
dataset = tfds.load("mnist", split=tfds.Split.TRAIN, as_supervised=True)
即可快速载入MNIST数据集。
对于特别巨大而无法完整载入内存的数据集,我们可以先将数据集处理为 TFRecord 格式,然后使用 tf.data.TFRocordDataset() 进行载入。详情请参考 后节:
数据集对象的预处理¶
tf.data.Dataset 类为我们提供了多种数据集预处理方法。最常用的如:
Dataset.map(f):对数据集中的每个元素应用函数f,得到一个新的数据集(这部分往往结合tf.io进行读写和解码文件,tf.image进行图像处理);Dataset.shuffle(buffer_size):将数据集打乱(设定一个固定大小的缓冲区(Buffer),取出前buffer_size个元素放入,并从缓冲区中随机采样,采样后的数据用后续数据替换);Dataset.batch(batch_size):将数据集分成批次,即对每batch_size个元素,使用tf.stack()在第0维合并,成为一个元素;
除此以外,还有 Dataset.repeat() (重复数据集的元素)、 Dataset.reduce() (与Map相对的聚合操作)、 Dataset.take() (截取数据集中的前若干个元素)等,可参考 API文档 进一步了解。
以下以MNIST数据集进行示例。
使用 Dataset.map() 将所有图片旋转90度:
def rot90(image, label):
image = tf.image.rot90(image)
return image, label
mnist_dataset = mnist_dataset.map(rot90)
for image, label in mnist_dataset:
plt.title(label.numpy())
plt.imshow(image.numpy()[:, :, 0])
plt.show()
输出
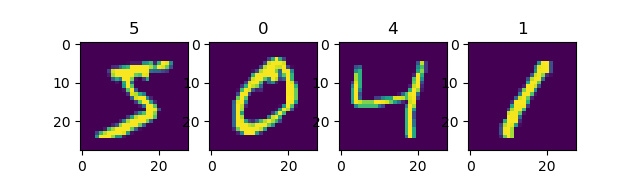
使用 Dataset.batch() 将数据集划分批次,每个批次的大小为4:
mnist_dataset = mnist_dataset.batch(4)
for images, labels in mnist_dataset: # image: [4, 28, 28, 1], labels: [4]
fig, axs = plt.subplots(1, 4)
for i in range(4):
axs[i].set_title(labels.numpy()[i])
axs[i].imshow(images.numpy()[i, :, :, 0])
plt.show()
输出
使用 Dataset.shuffle() 将数据打散后再设置批次,缓存大小设置为10000:
mnist_dataset = mnist_dataset.shuffle(buffer_size=10000).batch(4)
for images, labels in mnist_dataset:
fig, axs = plt.subplots(1, 4)
for i in range(4):
axs[i].set_title(labels.numpy()[i])
axs[i].imshow(images.numpy()[i, :, :, 0])
plt.show()
输出
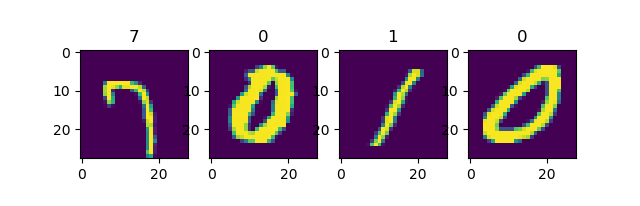
第一次运行¶
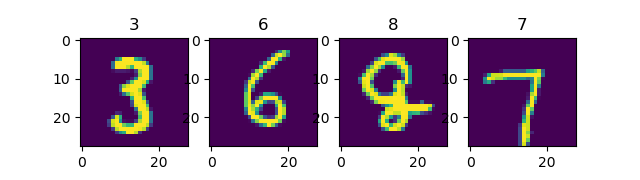
第二次运行¶
可见每次的数据都会被随机打散。
Dataset.shuffle() 时缓冲区大小 buffer_size 的设置
tf.data.Dataset 作为一个针对大规模数据设计的迭代器,本身无法方便地获得自身元素的数量或随机访问元素。因此,为了高效且较为充分地打散数据集,需要一些特定的方法。Dataset.shuffle() 采取了以下方法:
设定一个固定大小为
buffer_size的缓冲区(Buffer);初始化时,取出数据集中的前
buffer_size个元素放入缓冲区;每次需要从数据集中取元素时,即从缓冲区中随机采样一个元素并取出,然后从后续的元素中取出一个放回到之前被取出的位置,以维持缓冲区的大小。
因此,缓冲区的大小需要根据数据集的特性和数据排列顺序特点来进行合理的设置。比如:
当
buffer_size设置为1时,其实等价于没有进行任何打散;当数据集的标签顺序分布极为不均匀(例如二元分类时数据集前N个的标签为0,后N个的标签为1)时,较小的缓冲区大小会使得训练时取出的Batch数据很可能全为同一标签,从而影响训练效果。一般而言,数据集的顺序分布若较为随机,则缓冲区的大小可较小,否则则需要设置较大的缓冲区。
使用 tf.data 的并行化策略提高训练流程效率¶
当训练模型时,我们希望充分利用计算资源,减少CPU/GPU的空载时间。然而有时,数据集的准备处理非常耗时,使得我们在每进行一次训练前都需要花费大量的时间准备待训练的数据,而此时GPU只能空载而等待数据,造成了计算资源的浪费,如下图所示:
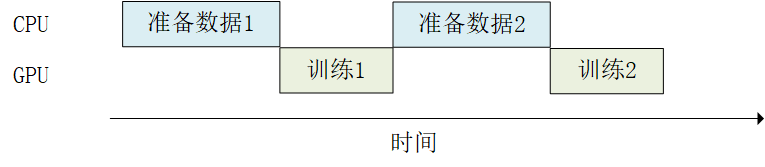
此时, tf.data 的数据集对象为我们提供了 Dataset.prefetch() 方法,使得我们可以让数据集对象 Dataset 在训练时预取出若干个元素,使得在GPU训练的同时CPU可以准备数据,从而提升训练流程的效率,如下图所示:
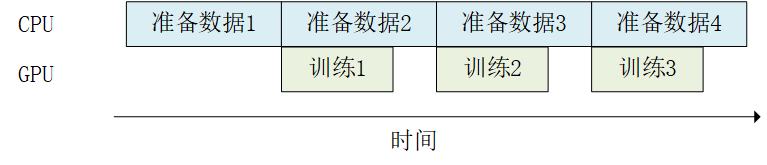
Dataset.prefetch() 的使用方法和前节的 Dataset.batch() 、 Dataset.shuffle() 等非常类似。继续以前节的MNIST数据集为例,若希望开启预加载数据,使用如下代码即可:
mnist_dataset = mnist_dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
此处参数 buffer_size 既可手工设置,也可设置为 tf.data.experimental.AUTOTUNE 从而由TensorFlow自动选择合适的数值。
与此类似, Dataset.map() 也可以利用多GPU资源,并行化地对数据项进行变换,从而提高效率。以前节的MNIST数据集为例,假设用于训练的计算机具有2核的CPU,我们希望充分利用多核心的优势对数据进行并行化变换(比如前节的旋转90度函数 rot90 ),可以使用以下代码:
mnist_dataset = mnist_dataset.map(map_func=rot90, num_parallel_calls=2)
其运行过程如下图所示:
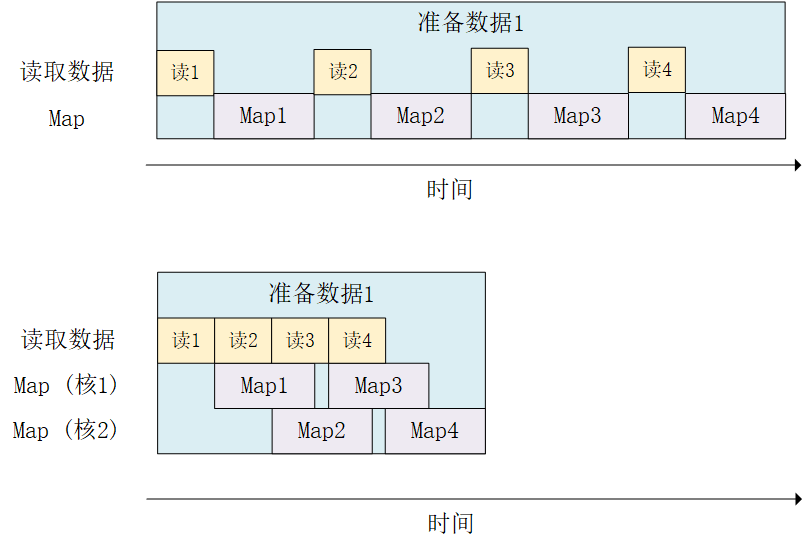
当然,这里同样可以将 num_parallel_calls 设置为 tf.data.experimental.AUTOTUNE 以让TensorFlow自动选择合适的数值。
除此以外,还有很多提升数据集处理性能的方式,可参考 TensorFlow文档 进一步了解。后文的实例中展示了tf.data并行化策略的强大性能,可 点此 查看。
数据集元素的获取与使用¶
构建好数据并预处理后,我们需要从其中迭代获取数据以用于训练。tf.data.Dataset 是一个Python的可迭代对象,因此可以使用For循环迭代获取数据,即:
dataset = tf.data.Dataset.from_tensor_slices((A, B, C, ...))
for a, b, c, ... in dataset:
# 对张量a, b, c等进行操作,例如送入模型进行训练
也可以使用 iter() 显式创建一个Python迭代器并使用 next() 获取下一个元素,即:
dataset = tf.data.Dataset.from_tensor_slices((A, B, C, ...))
it = iter(dataset)
a_0, b_0, c_0, ... = next(it)
a_1, b_1, c_1, ... = next(it)
Keras支持使用 tf.data.Dataset 直接作为输入。当调用 tf.keras.Model 的 fit() 和 evaluate() 方法时,可以将参数中的输入数据 x 指定为一个元素格式为 (输入数据, 标签数据) 的 Dataset ,并忽略掉参数中的标签数据 y 。例如,对于上述的MNIST数据集,常规的Keras训练方式是:
model.fit(x=train_data, y=train_label, epochs=num_epochs, batch_size=batch_size)
使用 tf.data.Dataset 后,我们可以直接传入 Dataset :
model.fit(mnist_dataset, epochs=num_epochs)
由于已经通过 Dataset.batch() 方法划分了数据集的批次,所以这里也无需提供批次的大小。
实例:cats_vs_dogs图像分类¶
以下代码以猫狗图片二分类任务为示例,展示了使用 tf.data 结合 tf.io 和 tf.image 建立 tf.data.Dataset 数据集,并进行训练和测试的完整过程。数据集可至 这里 下载。使用前须将数据集解压到代码中 data_dir 所设置的目录(此处默认设置为 C:/datasets/cats_vs_dogs ,可根据自己的需求进行修改)。
import tensorflow as tf
import os
num_epochs = 10
batch_size = 32
learning_rate = 0.001
data_dir = 'C:/datasets/cats_vs_dogs'
train_cats_dir = data_dir + '/train/cats/'
train_dogs_dir = data_dir + '/train/dogs/'
test_cats_dir = data_dir + '/valid/cats/'
test_dogs_dir = data_dir + '/valid/dogs/'
def _decode_and_resize(filename, label):
image_string = tf.io.read_file(filename) # 读取原始文件
image_decoded = tf.image.decode_jpeg(image_string) # 解码JPEG图片
image_resized = tf.image.resize(image_decoded, [256, 256]) / 255.0
return image_resized, label
if __name__ == '__main__':
# 构建训练数据集
train_cat_filenames = tf.constant([train_cats_dir + filename for filename in os.listdir(train_cats_dir)])
train_dog_filenames = tf.constant([train_dogs_dir + filename for filename in os.listdir(train_dogs_dir)])
train_filenames = tf.concat([train_cat_filenames, train_dog_filenames], axis=-1)
train_labels = tf.concat([
tf.zeros(train_cat_filenames.shape, dtype=tf.int32),
tf.ones(train_dog_filenames.shape, dtype=tf.int32)],
axis=-1)
train_dataset = tf.data.Dataset.from_tensor_slices((train_filenames, train_labels))
train_dataset = train_dataset.map(
map_func=_decode_and_resize,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
# 取出前buffer_size个数据放入buffer,并从其中随机采样,采样后的数据用后续数据替换
train_dataset = train_dataset.shuffle(buffer_size=23000)
train_dataset = train_dataset.batch(batch_size)
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(256, 256, 3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 5, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit(train_dataset, epochs=num_epochs)
使用以下代码进行测试:
# 构建测试数据集
test_cat_filenames = tf.constant([test_cats_dir + filename for filename in os.listdir(test_cats_dir)])
test_dog_filenames = tf.constant([test_dogs_dir + filename for filename in os.listdir(test_dogs_dir)])
test_filenames = tf.concat([test_cat_filenames, test_dog_filenames], axis=-1)
test_labels = tf.concat([
tf.zeros(test_cat_filenames.shape, dtype=tf.int32),
tf.ones(test_dog_filenames.shape, dtype=tf.int32)],
axis=-1)
test_dataset = tf.data.Dataset.from_tensor_slices((test_filenames, test_labels))
test_dataset = test_dataset.map(_decode_and_resize)
test_dataset = test_dataset.batch(batch_size)
print(model.metrics_names)
print(model.evaluate(test_dataset))
通过对以上示例进行性能测试,我们可以感受到 tf.data 的强大并行化性能。通过 prefetch() 的使用和在 map() 过程中加入 num_parallel_calls 参数,模型训练的时间可缩减至原来的一半甚至更低。测试结果如下:
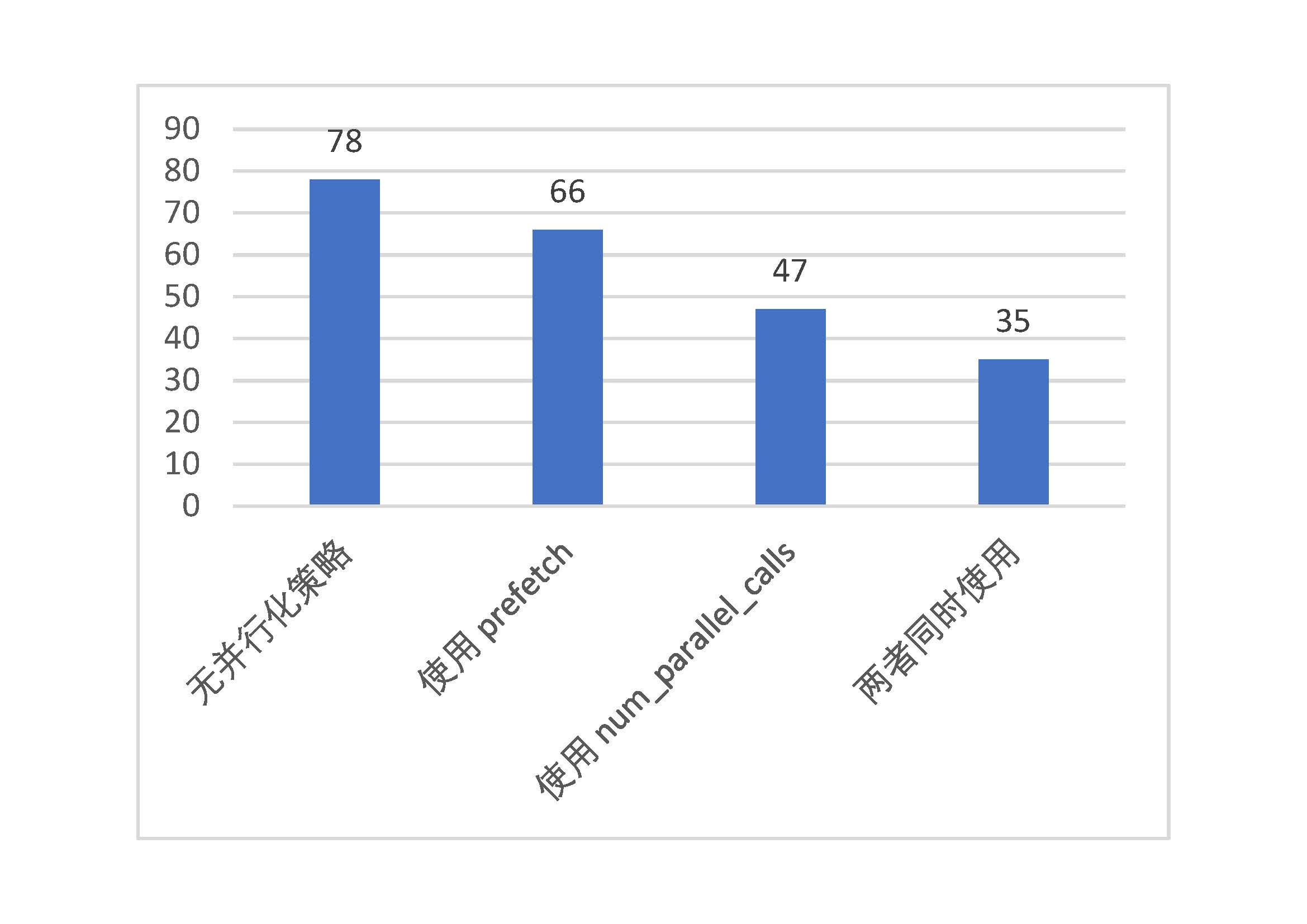
tf.data 的并行化策略性能测试(纵轴为每epoch训练所需时间,单位:秒)¶
TFRecord :TensorFlow数据集存储格式¶
TFRecord 是TensorFlow 中的数据集存储格式。当我们将数据集整理成 TFRecord 格式后,TensorFlow就可以高效地读取和处理这些数据集,从而帮助我们更高效地进行大规模的模型训练。
TFRecord可以理解为一系列序列化的 tf.train.Example 元素所组成的列表文件,而每一个 tf.train.Example 又由若干个 tf.train.Feature 的字典组成。形式如下:
# dataset.tfrecords
[
{ # example 1 (tf.train.Example)
'feature_1': tf.train.Feature,
...
'feature_k': tf.train.Feature
},
...
{ # example N (tf.train.Example)
'feature_1': tf.train.Feature,
...
'feature_k': tf.train.Feature
}
]
为了将形式各样的数据集整理为 TFRecord 格式,我们可以对数据集中的每个元素进行以下步骤:
读取该数据元素到内存;
将该元素转换为
tf.train.Example对象(每一个tf.train.Example由若干个tf.train.Feature的字典组成,因此需要先建立Feature的字典);将该
tf.train.Example对象序列化为字符串,并通过一个预先定义的tf.io.TFRecordWriter写入 TFRecord 文件。
而读取 TFRecord 数据则可按照以下步骤:
通过
tf.data.TFRecordDataset读入原始的 TFRecord 文件(此时文件中的tf.train.Example对象尚未被反序列化),获得一个tf.data.Dataset数据集对象;通过
Dataset.map方法,对该数据集对象中的每一个序列化的tf.train.Example字符串执行tf.io.parse_single_example函数,从而实现反序列化。
以下我们通过一个实例,展示将 上一节 中使用的cats_vs_dogs二分类数据集的训练集部分转换为TFRecord文件,并读取该文件的过程。
将数据集存储为 TFRecord 文件¶
首先,与 上一节 类似,我们进行一些准备工作,下载数据集 并解压到 data_dir ,初始化数据集的图片文件名列表及标签。
import tensorflow as tf
import os
data_dir = 'C:/datasets/cats_vs_dogs'
train_cats_dir = data_dir + '/train/cats/'
train_dogs_dir = data_dir + '/train/dogs/'
tfrecord_file = data_dir + '/train/train.tfrecords'
train_cat_filenames = [train_cats_dir + filename for filename in os.listdir(train_cats_dir)]
train_dog_filenames = [train_dogs_dir + filename for filename in os.listdir(train_dogs_dir)]
train_filenames = train_cat_filenames + train_dog_filenames
train_labels = [0] * len(train_cat_filenames) + [1] * len(train_dog_filenames) # 将 cat 类的标签设为0,dog 类的标签设为1
然后,通过以下代码,迭代读取每张图片,建立 tf.train.Feature 字典和 tf.train.Example 对象,序列化并写入TFRecord文件。
with tf.io.TFRecordWriter(tfrecord_file) as writer:
for filename, label in zip(train_filenames, train_labels):
image = open(filename, 'rb').read() # 读取数据集图片到内存,image 为一个 Byte 类型的字符串
feature = { # 建立 tf.train.Feature 字典
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])), # 图片是一个 Bytes 对象
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label])) # 标签是一个 Int 对象
}
example = tf.train.Example(features=tf.train.Features(feature=feature)) # 通过字典建立 Example
writer.write(example.SerializeToString()) # 将Example序列化并写入 TFRecord 文件
值得注意的是, tf.train.Feature 支持三种数据格式:
tf.train.BytesList:字符串或原始Byte文件(如图片),通过bytes_list参数传入一个由字符串数组初始化的tf.train.BytesList对象;tf.train.FloatList:浮点数,通过float_list参数传入一个由浮点数数组初始化的tf.train.FloatList对象;tf.train.Int64List:整数,通过int64_list参数传入一个由整数数组初始化的tf.train.Int64List对象。
如果只希望保存一个元素而非数组,传入一个只有一个元素的数组即可。
运行以上代码,不出片刻,我们即可在 tfrecord_file 所指向的文件地址获得一个 500MB 左右的 train.tfrecords 文件。
读取 TFRecord 文件¶
我们可以通过以下代码,读取之前建立的 train.tfrecords 文件,并通过 Dataset.map 方法,使用 tf.io.parse_single_example 函数对数据集中的每一个序列化的 tf.train.Example 对象解码。
raw_dataset = tf.data.TFRecordDataset(tfrecord_file) # 读取 TFRecord 文件
feature_description = { # 定义Feature结构,告诉解码器每个Feature的类型是什么
'image': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.int64),
}
def _parse_example(example_string): # 将 TFRecord 文件中的每一个序列化的 tf.train.Example 解码
feature_dict = tf.io.parse_single_example(example_string, feature_description)
feature_dict['image'] = tf.io.decode_jpeg(feature_dict['image']) # 解码JPEG图片
return feature_dict['image'], feature_dict['label']
dataset = raw_dataset.map(_parse_example)
这里的 feature_description 类似于一个数据集的“描述文件”,通过一个由键值对组成的字典,告知 tf.io.parse_single_example 函数每个 tf.train.Example 数据项有哪些Feature,以及这些Feature的类型、形状等属性。 tf.io.FixedLenFeature 的三个输入参数 shape 、 dtype 和 default_value (可省略)为每个Feature的形状、类型和默认值。这里我们的数据项都是单个的数值或者字符串,所以 shape 为空数组。
运行以上代码后,我们获得一个数据集对象 dataset ,这已经是一个可以用于训练的 tf.data.Dataset 对象了!我们从该数据集中读取元素并输出验证:
import matplotlib.pyplot as plt
for image, label in dataset:
plt.title('cat' if label == 0 else 'dog')
plt.imshow(image.numpy())
plt.show()
显示:

可见图片和标签都正确显示,数据集构建成功。
tf.function :图执行模式 *¶
虽然默认的即时执行模式(Eager Execution)为我们带来了灵活及易调试的特性,但在特定的场合,例如追求高性能或部署模型时,我们依然希望使用 TensorFlow 1.X 中默认的图执行模式(Graph Execution),将模型转换为高效的 TensorFlow 图模型。此时,TensorFlow 2 为我们提供了 tf.function 模块,结合 AutoGraph 机制,使得我们仅需加入一个简单的 @tf.function 修饰符,就能轻松将模型以图执行模式运行。
tf.function 基础使用方法¶
在 TensorFlow 2 中,推荐使用 tf.function (而非1.X中的 tf.Session )实现图执行模式,从而将模型转换为易于部署且高性能的TensorFlow图模型。只需要将我们希望以图执行模式运行的代码封装在一个函数内,并在函数前加上 @tf.function 即可,如下例所示。关于图执行模式的深入探讨可参考 附录 。
警告
并不是任何函数都可以被 @tf.function 修饰!@tf.function 使用静态编译将函数内的代码转换成计算图,因此对函数内可使用的语句有一定限制(仅支持Python语言的一个子集),且需要函数内的操作本身能够被构建为计算图。建议在函数内只使用TensorFlow的原生操作,不要使用过于复杂的Python语句,函数参数只包括TensorFlow张量或NumPy数组,并最好是能够按照计算图的思想去构建函数(换言之,@tf.function 只是给了你一种更方便的写计算图的方法,而不是一颗能给任何函数加速的 银子弹 )。详细内容可参考 AutoGraph Capabilities and Limitations 。建议配合 附录 一同阅读本节以获得较深入的理解。
import tensorflow as tf
import time
from zh.model.mnist.cnn import CNN
from zh.model.utils import MNISTLoader
num_batches = 1000
batch_size = 50
learning_rate = 0.001
data_loader = MNISTLoader()
model = CNN()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
@tf.function
def train_one_step(X, y):
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
# 注意这里使用了TensorFlow内置的tf.print()。@tf.function不支持Python内置的print方法
tf.print("loss", loss)
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
start_time = time.time()
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
train_one_step(X, y)
end_time = time.time()
print(end_time - start_time)
运行400个Batch进行测试,加入 @tf.function 的程序耗时35.5秒,未加入 @tf.function 的纯即时执行模式程序耗时43.8秒。可见 @tf.function 带来了一定的性能提升。一般而言,当模型由较多小的操作组成的时候, @tf.function 带来的提升效果较大。而当模型的操作数量较少,但单一操作均很耗时的时候,则 @tf.function 带来的性能提升不会太大。
tf.function 内在机制¶
当被 @tf.function 修饰的函数第一次被调用的时候,进行以下操作:
在即时执行模式关闭的环境下,函数内的代码依次运行。也就是说,每个
tf.方法都只是定义了计算节点,而并没有进行任何实质的计算。这与TensorFlow 1.X的图执行模式是一致的;使用AutoGraph将函数中的Python控制流语句转换成TensorFlow计算图中的对应节点(比如说
while和for语句转换为tf.while,if语句转换为tf.cond等等;基于上面的两步,建立函数内代码的计算图表示(为了保证图的计算顺序,图中还会自动加入一些
tf.control_dependencies节点);运行一次这个计算图;
基于函数的名字和输入的函数参数的类型生成一个哈希值,并将建立的计算图缓存到一个哈希表中。
在被 @tf.function 修饰的函数之后再次被调用的时候,根据函数名和输入的函数参数的类型计算哈希值,检查哈希表中是否已经有了对应计算图的缓存。如果是,则直接使用已缓存的计算图,否则重新按上述步骤建立计算图。
提示
对于熟悉 TensorFlow 1.X 的开发者,如果想要直接获得 tf.function 所生成的计算图以进行进一步处理和调试,可以使用被修饰函数的 get_concrete_function 方法。该方法接受的参数与被修饰函数相同。例如,为了获取前节被 @tf.function 修饰的函数 train_one_step 所生成的计算图,可以使用以下代码:
graph = train_one_step.get_concrete_function(X, y)
其中 graph 即为一个 tf.Graph 对象。
以下是一个测试题:
import tensorflow as tf
import numpy as np
@tf.function
def f(x):
print("The function is running in Python")
tf.print(x)
a = tf.constant(1, dtype=tf.int32)
f(a)
b = tf.constant(2, dtype=tf.int32)
f(b)
b_ = np.array(2, dtype=np.int32)
f(b_)
c = tf.constant(0.1, dtype=tf.float32)
f(c)
d = tf.constant(0.2, dtype=tf.float32)
f(d)
思考一下,上面这段程序的结果是什么?
答案是:
The function is running in Python
1
2
2
The function is running in Python
0.1
0.2
当计算 f(a) 时,由于是第一次调用该函数,TensorFlow进行了以下操作:
将函数内的代码依次运行了一遍(因此输出了文本);
构建了计算图,然后运行了一次该计算图(因此输出了1)。这里
tf.print(x)可以作为计算图的节点,但Python内置的print则不能被转换成计算图的节点。因此,计算图中只包含了tf.print(x)这一操作;将该计算图缓存到了一个哈希表中(如果之后再有类型为
tf.int32,shape为空的张量输入,则重复使用已构建的计算图)。
计算 f(b) 时,由于b的类型与a相同,所以TensorFlow重复使用了之前已构建的计算图并运行(因此输出了2)。这里由于并没有真正地逐行运行函数中的代码,所以函数第一行的文本输出代码没有运行。计算 f(b_) 时,TensorFlow自动将numpy的数据结构转换成了TensorFlow中的张量,因此依然能够复用之前已构建的计算图。
计算 f(c) 时,虽然张量 c 的shape和 a 、 b 均相同,但类型为 tf.float32 ,因此TensorFlow重新运行了函数内代码(从而再次输出了文本)并建立了一个输入为 tf.float32 类型的计算图。
计算 f(d) 时,由于 d 和 c 的类型相同,所以TensorFlow复用了计算图,同理没有输出文本。
而对于 @tf.function 对Python内置的整数和浮点数类型的处理方式,我们通过以下示例展现:
f(d)
f(1)
f(2)
f(1)
f(0.1)
f(0.2)
f(0.1)
结果为:
The function is running in Python
1
The function is running in Python
2
1
The function is running in Python
0.1
The function is running in Python
0.2
0.1
简而言之,对于Python内置的整数和浮点数类型,只有当值完全一致的时候, @tf.function 才会复用之前建立的计算图,而并不会自动将Python内置的整数或浮点数等转换成张量。因此,当函数参数包含Python内置整数或浮点数时,需要格外小心。一般而言,应当只在指定超参数等少数场合使用Python内置类型作为被 @tf.function 修饰的函数的参数。
下一个思考题:
import tensorflow as tf
a = tf.Variable(0.0)
@tf.function
def g():
a.assign(a + 1.0)
return a
print(g())
print(g())
print(g())
这段代码的输出是:
tf.Tensor(1.0, shape=(), dtype=float32)
tf.Tensor(2.0, shape=(), dtype=float32)
tf.Tensor(3.0, shape=(), dtype=float32)
正如同正文里的例子一样,你可以在被 @tf.function 修饰的函数里调用 tf.Variable 、 tf.keras.optimizers 、 tf.keras.Model 等包含有变量的数据结构。一旦被调用,这些结构将作为隐含的参数提供给函数。当这些结构内的值在函数内被修改时,在函数外也同样生效。
AutoGraph:将Python控制流转换为TensorFlow计算图¶
前面提到,@tf.function 使用名为AutoGraph的机制将函数中的Python控制流语句转换成TensorFlow计算图中的对应节点。以下是一个示例,使用 tf.autograph 模块的低层API tf.autograph.to_code 将函数 square_if_positive 转换成TensorFlow计算图:
import tensorflow as tf
@tf.function
def square_if_positive(x):
if x > 0:
x = x * x
else:
x = 0
return x
a = tf.constant(1)
b = tf.constant(-1)
print(square_if_positive(a), square_if_positive(b))
print(tf.autograph.to_code(square_if_positive.python_function))
输出:
tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(0, shape=(), dtype=int32)
def tf__square_if_positive(x):
do_return = False
retval_ = ag__.UndefinedReturnValue()
cond = x > 0
def get_state():
return ()
def set_state(_):
pass
def if_true():
x_1, = x,
x_1 = x_1 * x_1
return x_1
def if_false():
x = 0
return x
x = ag__.if_stmt(cond, if_true, if_false, get_state, set_state)
do_return = True
retval_ = x
cond_1 = ag__.is_undefined_return(retval_)
def get_state_1():
return ()
def set_state_1(_):
pass
def if_true_1():
retval_ = None
return retval_
def if_false_1():
return retval_
retval_ = ag__.if_stmt(cond_1, if_true_1, if_false_1, get_state_1, set_state_1)
return retval_
我们注意到,原函数中的Python控制流 if...else... 被转换为了 x = ag__.if_stmt(cond, if_true, if_false, get_state, set_state) 这种计算图式的写法。AutoGraph起到了类似编译器的作用,能够帮助我们通过更加自然的Python控制流轻松地构建带有条件/循环的计算图,而无需手动使用TensorFlow的API进行构建。
使用传统的 tf.Session¶
不过,如果你依然钟情于TensorFlow传统的图执行模式也没有问题。TensorFlow 2 提供了 tf.compat.v1 模块以支持TensorFlow 1.X版本的API。同时,只要在编写模型的时候稍加注意,Keras的模型是可以同时兼容即时执行模式和图执行模式的。注意,在图执行模式下, model(input_tensor) 只需运行一次以完成图的建立操作。
例如,通过以下代码,同样可以在MNIST数据集上训练前面所建立的MLP或CNN模型:
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
# 建立计算图
X_placeholder = tf.compat.v1.placeholder(name='X', shape=[None, 28, 28, 1], dtype=tf.float32)
y_placeholder = tf.compat.v1.placeholder(name='y', shape=[None], dtype=tf.int32)
y_pred = model(X_placeholder)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y_placeholder, y_pred=y_pred)
loss = tf.reduce_mean(loss)
train_op = optimizer.minimize(loss)
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# 建立Session
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
# 使用Session.run()将数据送入计算图节点,进行训练以及计算损失函数
_, loss_value = sess.run([train_op, loss], feed_dict={X_placeholder: X, y_placeholder: y})
print("batch %d: loss %f" % (batch_index, loss_value))
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict(data_loader.test_data[start_index: end_index])
sess.run(sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred))
print("test accuracy: %f" % sess.run(sparse_categorical_accuracy.result()))
关于图执行模式的更多内容可参见 ../appendix/static。
tf.TensorArray :TensorFlow 动态数组 *¶
在部分网络结构,尤其是涉及到时间序列的结构中,我们可能需要将一系列张量以数组的方式依次存放起来,以供进一步处理。当然,在即时执行模式下,你可以直接使用一个Python列表(List)存放数组。不过,如果你需要基于计算图的特性(例如使用 @tf.function 加速模型运行或者使用SavedModel导出模型),就无法使用这种方式了。因此,TensorFlow提供了 tf.TensorArray ,一种支持计算图特性的TensorFlow动态数组。
其声明的方式为:
arr = tf.TensorArray(dtype, size, dynamic_size=False):声明一个大小为size,类型为dtype的TensorArrayarr。如果将dynamic_size参数设置为True,则该数组会自动增长空间。
其读取和写入的方法为:
write(index, value):将value写入数组的第index个位置;read(index):读取数组的第index个值;
除此以外,TensorArray还包括 stack() 、 unstack() 等常用操作,可参考 文档 以了解详情。
请注意,由于需要支持计算图, tf.TensorArray 的 write() 方法是不可以忽略左值的!也就是说,在图执行模式下,必须按照以下的形式写入数组:
arr = arr.write(index, value)
这样才可以正常生成一个计算图操作,并将该操作返回给 arr 。而不可以写成:
arr.write(index, value) # 生成的计算图操作没有左值接收,从而丢失
一个简单的示例如下:
import tensorflow as tf
@tf.function
def array_write_and_read():
arr = tf.TensorArray(dtype=tf.float32, size=3)
arr = arr.write(0, tf.constant(0.0))
arr = arr.write(1, tf.constant(1.0))
arr = arr.write(2, tf.constant(2.0))
arr_0 = arr.read(0)
arr_1 = arr.read(1)
arr_2 = arr.read(2)
return arr_0, arr_1, arr_2
a, b, c = array_write_and_read()
print(a, b, c)
输出:
tf.Tensor(0.0, shape=(), dtype=float32) tf.Tensor(1.0, shape=(), dtype=float32) tf.Tensor(2.0, shape=(), dtype=float32)
tf.config:GPU的使用与分配 *¶
指定当前程序使用的GPU¶
很多时候的场景是:实验室/公司研究组里有许多学生/研究员需要共同使用一台多GPU的工作站,而默认情况下TensorFlow会使用其所能够使用的所有GPU,这时就需要合理分配显卡资源。
首先,通过 tf.config.list_physical_devices ,我们可以获得当前主机上某种特定运算设备类型(如 GPU 或 CPU )的列表,例如,在一台具有4块GPU和一个CPU的工作站上运行以下代码:
gpus = tf.config.list_physical_devices(device_type='GPU')
cpus = tf.config.list_physical_devices(device_type='CPU')
print(gpus, cpus)
输出:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU')]
[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')]
可见,该工作站具有4块GPU:GPU:0 、 GPU:1 、 GPU:2 、 GPU:3 ,以及一个CPU CPU:0 。
然后,通过 tf.config.set_visible_devices ,可以设置当前程序可见的设备范围(当前程序只会使用自己可见的设备,不可见的设备不会被当前程序使用)。例如,如果在上述4卡的机器中我们需要限定当前程序只使用下标为0、1的两块显卡(GPU:0 和 GPU:1),可以使用以下代码:
gpus = tf.config.list_physical_devices(device_type='GPU')
tf.config.set_visible_devices(devices=gpus[0:2], device_type='GPU')
如果完全不想使用 GPU ,向 devices 参数传入空列表即可,即
tf.config.set_visible_devices(devices=[], device_type='GPU')
小技巧
使用环境变量 CUDA_VISIBLE_DEVICES 也可以控制程序所使用的GPU。假设发现四卡的机器上显卡0,1使用中,显卡2,3空闲,Linux终端输入:
export CUDA_VISIBLE_DEVICES=2,3
或在代码中加入
import os
os.environ['CUDA_VISIBLE_DEVICES'] = "2,3"
即可指定程序只在显卡2,3上运行。
设置显存使用策略¶
默认情况下,TensorFlow将使用几乎所有可用的显存,以避免内存碎片化所带来的性能损失。不过,TensorFlow提供两种显存使用策略,让我们能够更灵活地控制程序的显存使用方式:
仅在需要时申请显存空间(程序初始运行时消耗很少的显存,随着程序的运行而动态申请显存);
限制消耗固定大小的显存(程序不会超出限定的显存大小,若超出的报错)。
可以通过 tf.config.experimental.set_memory_growth 将GPU的显存使用策略设置为“仅在需要时申请显存空间”。以下代码将所有GPU设置为仅在需要时申请显存空间:
gpus = tf.config.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(device=gpu, enable=True)
以下代码通过 tf.config.set_logical_device_configuration 选项并传入 tf.config.LogicalDeviceConfiguration 实例,设置TensorFlow固定消耗 GPU:0 的1GB显存(其实可以理解为建立了一个显存大小为1GB的“虚拟GPU”):
gpus = tf.config.list_physical_devices(device_type='GPU')
tf.config.set_logical_device_configuration(
gpus[0],
[tf.config.LogicalDeviceConfiguration(memory_limit=1024)])
提示
TensorFlow 1.X 的 图执行模式 下,可以在实例化新的session时传入 tf.compat.v1.ConfigPhoto 类来设置TensorFlow使用显存的策略。具体方式是实例化一个 tf.ConfigProto 类,设置参数,并在创建 tf.compat.v1.Session 时指定Config参数。以下代码通过 allow_growth 选项设置TensorFlow仅在需要时申请显存空间:
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.compat.v1.Session(config=config)
以下代码通过 per_process_gpu_memory_fraction 选项设置TensorFlow固定消耗40%的GPU显存:
config = tf.compat.v1.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
tf.compat.v1.Session(config=config)
单GPU模拟多GPU环境¶
当我们的本地开发环境只有一个GPU,但却需要编写多GPU的程序在工作站上进行训练任务时,TensorFlow为我们提供了一个方便的功能,可以让我们在本地开发环境中建立多个模拟GPU,从而让多GPU的程序调试变得更加方便。以下代码在实体GPU GPU:0 的基础上建立了两个显存均为2GB的虚拟GPU。
gpus = tf.config.list_physical_devices('GPU')
tf.config.set_logical_device_configuration(
gpus[0],
[tf.config.LogicalDeviceConfiguration(memory_limit=2048),
tf.config.LogicalDeviceConfiguration(memory_limit=2048)])
我们在 单机多卡训练 的代码前加入以上代码,即可让原本为多GPU设计的代码在单GPU环境下运行。当输出设备数量时,程序会输出:
Number of devices: 2