TensorFlow Lite(Jinpeng)¶
TensorFlow Lite是TensorFlow在移动和IoT等边缘设备端的解决方案,提供了Java、Python和C++ API库,可以运行在Android、iOS和Raspberry Pi等设备上。2019年是5G元年,万物互联的时代已经来临,作为TensorFlow在边缘设备上的基础设施,TFLite将会是愈发重要的角色。
目前TFLite只提供了推理功能,在服务器端进行训练后,经过如下简单处理即可部署到边缘设备上。
模型转换:由于边缘设备计算等资源有限,使用TensorFlow训练好的模型,模型太大、运行效率比较低,不能直接在移动端部署,需要通过相应工具进行转换成适合边缘设备的格式。
边缘设备部署:本节以android为例,简单介绍如何在android应用中部署转化后的模型,完成Mnist图片的识别。
模型转换¶
转换工具有两种:命令行工具和Python API
TF2.0对模型转换工具发生了非常大的变化,推荐大家使用Python API进行转换,命令行工具只提供了基本的转化功能。转换后的原模型为 FlatBuffers 格式。 FlatBuffers 原来主要应用于游戏场景,是谷歌为了高性能场景创建的序列化库,相比Protocol Buffer有更高的性能和更小的大小等优势,更适合于边缘设备部署。
转换方式有两种:Float格式和Quantized格式
为了熟悉两种方式我们都会使用,针对Float格式的,先使用命令行工具 tflite_convert ,其跟随TensorFlow一起安装(见 一般安装步骤 )。
在终端执行如下命令:
tflite_convert -h
输出结果如下,即该命令的使用方法:
usage: tflite_convert [-h] --output_file OUTPUT_FILE
(--saved_model_dir SAVED_MODEL_DIR | --keras_model_file KERAS_MODEL_FILE)
--output_file OUTPUT_FILE
Full filepath of the output file.
--saved_model_dir SAVED_MODEL_DIR
Full path of the directory containing the SavedModel.
--keras_model_file KERAS_MODEL_FILE
Full filepath of HDF5 file containing tf.Keras model.
在 TensorFlow模型导出 中,我们知道TF2.0支持两种模型导出方法和格式SavedModel和Keras Sequential。
SavedModel导出模型转换:
tflite_convert --saved_model_dir=saved/1 --output_file=mnist_savedmodel.tflite
Keras Sequential导出模型转换:
tflite_convert --keras_model_file=mnist_cnn.h5 --output_file=mnist_sequential.tflite
到此,已经得到两个TensorFlow Lite模型。因为两者后续操作基本一致,我们只处理SavedModel格式的,Keras Sequential的转换可以按类似方法处理。
Android部署¶
现在开始在Android环境部署,为了获取SDK和gradle编译环境等资源,需要先给Android Studio配置proxy或者使用镜像。
配置build.gradle
将 build.gradle 中的maven源 google() 和 jcenter() 分别替换为阿里云镜像地址,如下:
buildscript {
repositories {
maven { url 'https://maven.aliyun.com/nexus/content/repositories/google' }
maven { url 'https://maven.aliyun.com/nexus/content/repositories/jcenter' }
}
dependencies {
classpath 'com.android.tools.build:gradle:3.5.1'
}
}
allprojects {
repositories {
maven { url 'https://maven.aliyun.com/nexus/content/repositories/google' }
maven { url 'https://maven.aliyun.com/nexus/content/repositories/jcenter' }
}
}
配置app/build.gradle
新建一个Android Project,打开 app/build.gradle 添加如下信息:
android {
aaptOptions {
noCompress "tflite" // 编译apk时,不压缩tflite文件
}
}
dependencies {
implementation 'org.tensorflow:tensorflow-lite:1.14.0'
}
其中,
aaptOptions设置tflite文件不压缩,确保后面tflite文件可以被Interpreter正确加载。org.tensorflow:tensorflow-lite的最新版本号可以在这里查询 https://bintray.com/google/tensorflow/tensorflow-lite
设置好后,sync和build整个工程,如果build成功说明,配置成功。
添加tflite文件到assets文件夹
在app目录先新建assets目录,并将 mnist_savedmodel.tflite 文件保存到assets目录。重新编译apk,检查新编译出来的apk的assets文件夹是否有 mnist_cnn.tflite 文件。
点击菜单Build->Build APK(s)触发apk编译,apk编译成功点击右下角的EventLog。点击最后一条信息中的 analyze 链接,会触发apk analyzer查看新编译出来的apk,若在assets目录下存在 mnist_savedmodel.tflite ,则编译打包成功,如下:
assets
|__mnist_savedmodel.tflite
加载模型
使用如下函数将 mnist_savedmodel.tflite 文件加载到memory-map中,作为Interpreter实例化的输入
/** Memory-map the model file in Assets. */
private MappedByteBuffer loadModelFile(Activity activity) throws IOException {
AssetFileDescriptor fileDescriptor = activity.getAssets().openFd(mModelPath);
FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor());
FileChannel fileChannel = inputStream.getChannel();
long startOffset = fileDescriptor.getStartOffset();
long declaredLength = fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
}
提示
memory-map可以把整个文件映射到虚拟内存中,用于提升tflite模型的读取性能。更多请参考: JDK API介绍
实例化Interpreter,其中acitivity是为了从assets中获取模型,因为我们把模型编译到assets中,只能通过 getAssets() 打开。
mTFLite = new Interpreter(loadModelFile(activity));
memory-map后的 MappedByteBuffer 直接作为 Interpreter 的输入, mTFLite ( Interpreter )就是转换后模型的运行载体。
运行输入
我们使用MNIST test测试集中的图片作为输入,mnist图像大小28*28,单像素,因为我们输入的数据需要设置成如下格式
//Float模型相关参数
// com/dpthinker/mnistclassifier/model/FloatSavedModelConfig.java
protected void setConfigs() {
setModelName("mnist_savedmodel.tflite");
setNumBytesPerChannel(4);
setDimBatchSize(1);
setDimPixelSize(1);
setDimImgWeight(28);
setDimImgHeight(28);
setImageMean(0);
setImageSTD(255.0f);
}
// 初始化
// com/dpthinker/mnistclassifier/classifier/BaseClassifier.java
private void initConfig(BaseModelConfig config) {
this.mModelConfig = config;
this.mNumBytesPerChannel = config.getNumBytesPerChannel();
this.mDimBatchSize = config.getDimBatchSize();
this.mDimPixelSize = config.getDimPixelSize();
this.mDimImgWidth = config.getDimImgWeight();
this.mDimImgHeight = config.getDimImgHeight();
this.mModelPath = config.getModelName();
}
将MNIST图片转化成 ByteBuffer ,并保持到 imgData ( ByteBuffer )中
// 将输入的Bitmap转化为Interpreter可以识别的ByteBuffer
// com/dpthinker/mnistclassifier/classifier/BaseClassifier.java
protected ByteBuffer convertBitmapToByteBuffer(Bitmap bitmap) {
int[] intValues = new int[mDimImgWidth * mDimImgHeight];
scaleBitmap(bitmap).getPixels(intValues,
0, bitmap.getWidth(), 0, 0, bitmap.getWidth(), bitmap.getHeight());
ByteBuffer imgData = ByteBuffer.allocateDirect(
mNumBytesPerChannel * mDimBatchSize * mDimImgWidth * mDimImgHeight * mDimPixelSize);
imgData.order(ByteOrder.nativeOrder());
imgData.rewind();
// Convert the image toFloating point.
int pixel = 0;
for (int i = 0; i < mDimImgWidth; ++i) {
for (int j = 0; j < mDimImgHeight; ++j) {
//final int val = intValues[pixel++];
int val = intValues[pixel++];
mModelConfig.addImgValue(imgData, val); //添加把Pixel数值转化并添加到ByteBuffer
}
}
return imgData;
}
// mModelConfig.addImgValue定义
// com/dpthinker/mnistclassifier/model/FloatSavedModelConfig.java
public void addImgValue(ByteBuffer imgData, int val) {
imgData.putFloat(((val & 0xFF) - getImageMean()) / getImageSTD());
}
convertBitmapToByteBuffer 的输出即为模型运行的输入。
运行输出
定义一个1*10的多维数组,因为我们只有10个label,具体代码如下
privateFloat[][] mLabelProbArray = newFloat[1][10];
运行结束后,每个二级元素都是一个label的概率。
运行及结果处理
开始运行模型,具体代码如下
mTFLite.run(imgData, mLabelProbArray);
针对某个图片,运行后 mLabelProbArray 的内容就是各个label识别的概率。对他们进行排序,找出Top的label并界面呈现给用户.
在Android应用中,笔者使用了 View.OnClickListener() 触发 "image/*" 类型的 Intent.ACTION_GET_CONTENT ,进而获取设备上的图片(只支持MNIST标准图片)。然后,通过 RadioButtion 的选择情况,确认加载哪种转换后的模型,并触发真正分类操作。这部分比较简单,请读者自行阅读代码即可,不再展开介绍。
选取一张MNIST测试集中的图片进行测试,得到结果如下:

提示
注意我们这里直接用 mLabelProbArray 数值中的index作为label了,因为MNIST的label完全跟index从0到9匹配。如果是其他的分类问题,需要根据实际情况进行转换。
Quantization模型转换¶
提示
Quantized模型是对原模型进行转换过程中,将float参数转化为uint8类型,进而产生的模型会更小、运行更快,但是精度会有所下降。
前面我们介绍了Float 模型的转换方法,接下来我们要展示下 Quantized 模型,在TF1.0上,可以使用命令行工具转换 Quantized模型。在笔者尝试的情况看在TF2.0上,命令行工具目前只能转换为Float 模型,Python API只能转换为 Quantized 模型。
Python API转换方法如下:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model('saved/1')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
open("mnist_savedmodel_quantized.tflite", "wb").write(tflite_quant_model)
最终转换后的 Quantized模型即为同级目录下的 mnist_savedmodel_quantized.tflite 。
相对TF1.0,上面的方法简化了很多,不需要考虑各种各样的参数,谷歌一直在优化开发者的使用体验。
在TF1.0上,我们可以使用 tflite_convert 获得模型具体结构,然后通过graphviz转换为pdf或png等方便查看。
在TF2.0上,提供了新的一步到位的工具 visualize.py ,直接转换为html文件,除了模型结构,还有更清晰的关键信息总结。
提示
visualize.py 目前看应该还是开发阶段,使用前需要先从github下载最新的 TensorFlow 和 FlatBuffers 源码,并且两者要在同一目录,因为 visualize.py 源码中是按两者在同一目录写的调用路径。
下载 TensorFlow:
git clone git@github.com:tensorflow/tensorflow.git
下载 FlatBuffers:
git clone git@github.com:google/flatbuffers.git
编译 FlatBuffers:(笔者使用的Mac,其他平台请大家自行配置,应该不麻烦)
下载cmake:执行
brew install cmake设置编译环境:在
FlatBuffers的根目录,执行cmake -G "Unix Makefiles" -DCMAKE_BUILD_TYPE=Release编译:在
FlatBuffers的根目录,执行make
编译完成后,会在跟目录生成 flatc,这个可执行文件是 visualize.py 运行所依赖的。
visualize.py使用方法
在tensorflow/tensorflow/lite/tools目录下,执行如下命令
python visualize.py mnist_savedmodel_quantized.tflite mnist_savedmodel_quantized.html
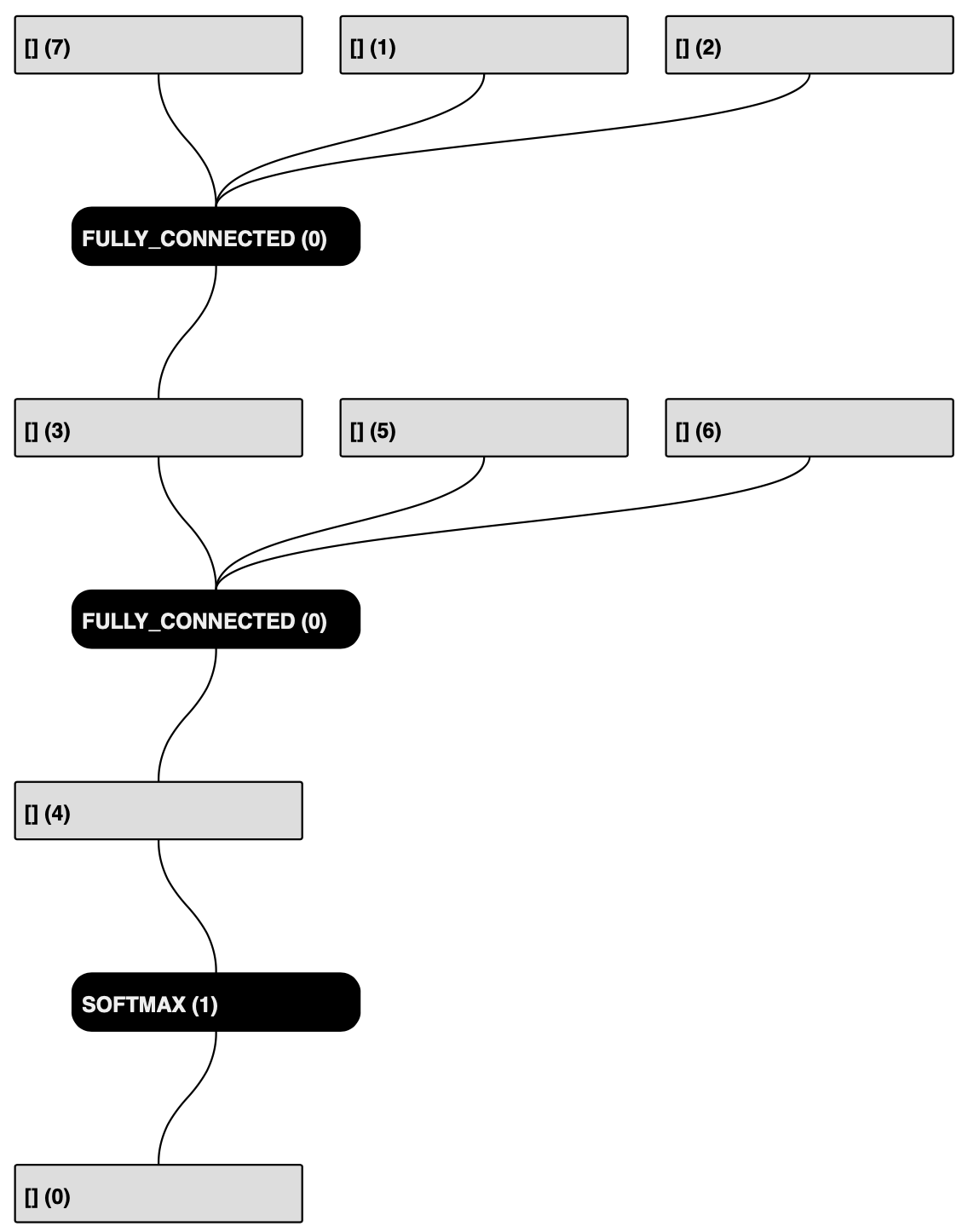
生成可视化报告的关键信息
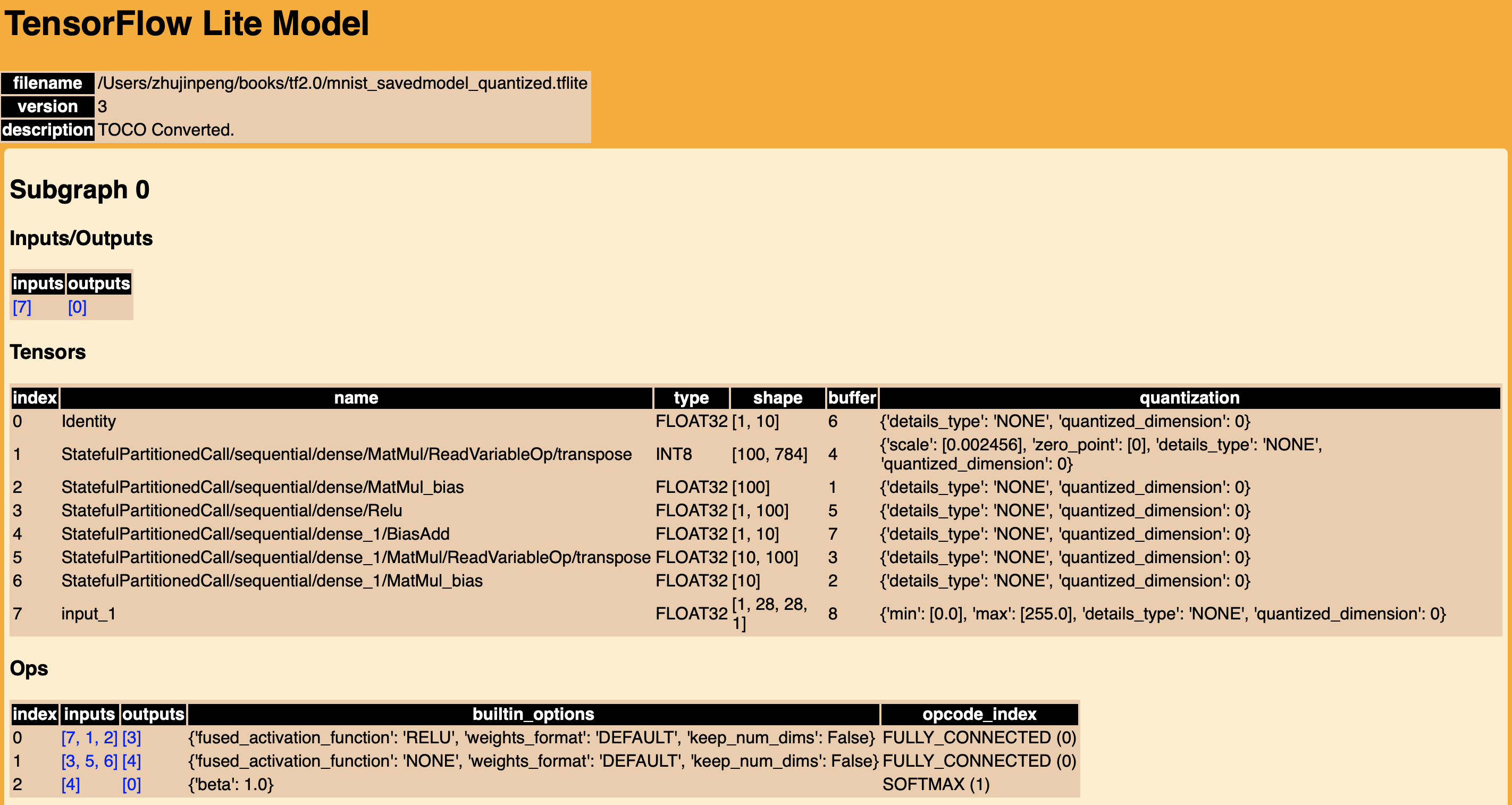
模型结构
可见,Input/Output格式都是 FLOAT32 的多维数组,Input的min和max分别是0.0和255.0。
跟Float模型对比,Input/Output格式是一致的,所以可以复用Float模型Android部署过程中的配置。
提示
暂不确定这里是否是TF2.0上的优化,如果是这样的话,对开发者来说是非常友好的,如此就归一化了Float和Quantized模型处理了。
具体配置如下:
// Quantized模型相关参数
// com/dpthinker/mnistclassifier/model/QuantSavedModelConfig.java
public class QuantSavedModelConfig extends BaseModelConfig {
@Override
protected void setConfigs() {
setModelName("mnist_savedmodel_quantized.tflite");
setNumBytesPerChannel(4);
setDimBatchSize(1);
setDimPixelSize(1);
setDimImgWeight(28);
setDimImgHeight(28);
setImageMean(0);
setImageSTD(255.0f);
}
@Override
public void addImgValue(ByteBuffer imgData, int val) {
imgData.putFloat(((val & 0xFF) - getImageMean()) / getImageSTD());
}
}
运行效果如下:
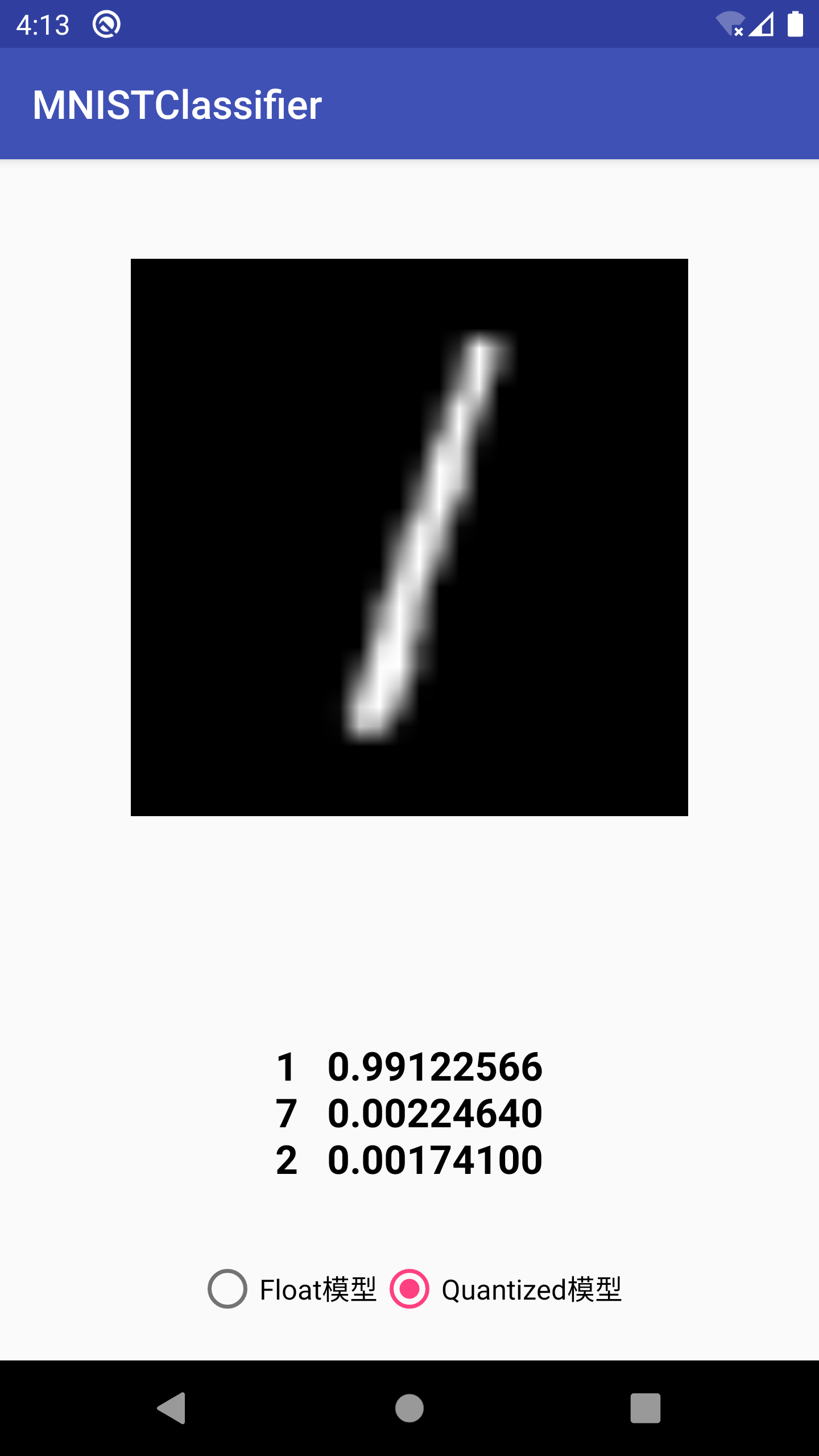
Float模型与 Quantized模型大小与性能对比:
模型类别 |
Float |
Quantized |
|---|---|---|
模型大小 |
312K |
82K |
运行性能 |
5.858854ms |
1.439062ms |
可见, Quantized模型在模型大小和运行性能上相对Float模型都有非常大的提升。不过,在笔者试验的过程中,发现有些图片在Float模型上识别正确的,在 Quantized模型上会识别错,可见 Quantization 对模型的识别精度还是有影响的。在边缘设备上资源有限,需要在模型大小、运行速度与识别精度上找到一个权衡。
总结¶
本节介绍了如何从零开始部署TFLite到Android应用中,包括:
如何将训练好的MNIST SavedModel模型,转换为Float模型和 Quantized模型
如何使用
visualize.py和解读其结果信息如何将转换后的模型部署到Android应用中
笔者刚开始写这部分内容的时候还是TF1.0,在最近(2019年10月初)跟TF2.0的时候,发现有了很多变化,整体上是比原来更简单了。不过文档部分很多还是讲的比较模糊,很多地方还是需要看源码摸索。
提示
本节Android相关代码存放路径:
https://github.com/snowkylin/tensorflow-handbook/tree/master/source/android